Comment l’IA générative fonctionne réellement
Le lancement de IA générative par OpenAI à la fin de l’année dernière a été phénoménal – même ma grand-mère en parle. Sa capacité à générer un langage de type humain a incité les gens à expérimenter son potentiel dans divers produits. Son lancement très réussi a même mis la pression sur des géants de la technologie comme Google, qui se sont empressés de lancer leur propre version de IA générative.
Mais soyons honnêtes, pour les gestionnaires de produits, les concepteurs et les entrepreneurs non techniques, le fonctionnement interne de IA générative peut sembler être une boîte noire magique. Ne vous inquiétez pas ! Dans ce blog, je vais essayer d’expliquer la technologie et le modèle derrière IA générative aussi simplement que possible. À la fin de ce billet, vous aurez une bonne compréhension de ce que IA générative peut faire, et comment il réalise sa magie.
Le transformateur et la chronologie de GPT
Avant de nous plonger dans le mécanisme de IA générative, jetons un coup d’œil rapide à la chronologie du développement de l’architecture des transformateurs de modèles de langue et aux différentes versions de GPT, afin que vous puissiez avoir une meilleure idée de la façon dont les choses ont évolué vers le IA générative que nous avons aujourd’hui.
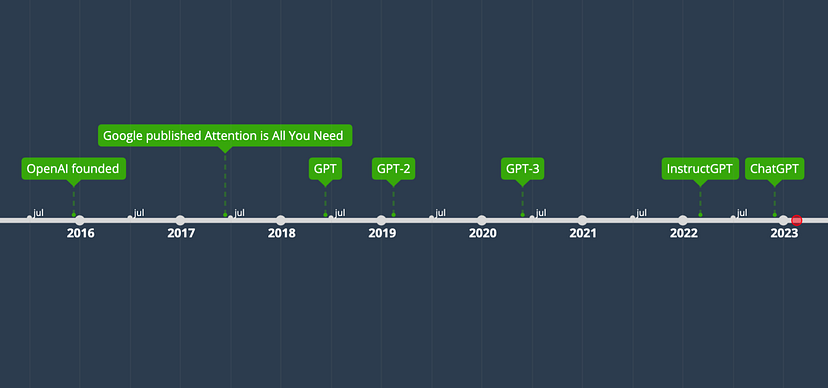
Chronologie des transformateurs, de GPT et de IA générative. Image par l’auteur.
- OpenAI a été fondée par Sam Altman, Elon Musk, Greg Brockman, Peter Thiel et d’autres. OpenAI développe de nombreux modèles d’IA différents autres que GPT.
- Google publie l’article Attention is All You Need, qui présente l’architecture Transformer [2]. Le transformateur est une architecture de réseau neuronal qui jette les bases de nombreux modèles de langage de grande envergure (SOTA) à la pointe de la technologie, comme GPT.
- GPT est présenté dans Improving Language Understanding by Generative Pre-training [3]. Il est basé sur une architecture de transformateur modifiée et pré-entraîné sur un grand corpus.
- GPT-2 est introduit dans Language Models are Unsupervised Multitask Learners [4], qui peut effectuer une série de tâches sans supervision explicite lors de la formation.
- GPT-3 est introduit dans Language Models are Few-Shot Learners [5], qui peut obtenir de bons résultats avec peu d’exemples dans l’invite sans réglage fin.
- InstructGPT est introduit dans Training language models to follow instructions with human feedback [6], qui peut mieux suivre les instructions de l’utilisateur grâce à un réglage fin avec le feedback humain.
- IA générative, un frère d’InstructGPT, est présenté dans IA générative : Optimizing Language Models for Dialogue. Il peut interagir avec des humains dans des conversations, grâce à l’ajustement fin avec des exemples humains et l’apprentissage par renforcement à partir du feedback humain (RLHF).
La chronologie montre que le GPT a évolué à partir de l’architecture originale du transformateur et a acquis ses capacités grâce à de nombreuses itérations. Si vous ne comprenez pas les termes tels que transformateurs, préformation, réglage fin ou apprentissage par renforcement à partir de la rétroaction humaine, ne vous inquiétez pas ! Je les expliquerai tous dans les sections suivantes.
Plonger dans les profondeurs des modèles
Maintenant que vous savez que IA générative est basé sur les transformateurs et les modèles GPT précédents, examinons de plus près les composants de ces modèles et leur fonctionnement. Ce n’est pas grave si vous n’êtes pas familier avec l’apprentissage profond, les réseaux neuronaux ou l’IA – je vais laisser de côté les équations et expliquer les concepts à l’aide d’analogies et d’exemples.
Dans les sections suivantes, je commencerai par une vue d’ensemble des modèles de langage et de la PNL, avant de passer à l’architecture originale du transformateur, puis à la façon dont GPT a adapté l’architecture du transformateur, et enfin à la façon dont IA générative est affiné sur la base de GPT.
Modèles de langage et NLP
Il existe de nombreux types de modèles d’IA ou d’apprentissage profond. Pour les tâches de traitement du langage naturel (NLP) comme les conversations, la reconnaissance vocale, la traduction et le résumé, nous nous tournerons vers les modèles de langage pour nous aider.
Les modèles de langage peuvent apprendre une bibliothèque de textes (appelée corpus) et prédire des mots ou des séquences de mots avec des distributions probabilistes, c’est-à-dire la probabilité qu’un mot ou une séquence se produise. Par exemple, lorsque vous dites “Tom aime manger …”, la probabilité que le mot suivant soit “pizza” est plus élevée que “table”. S’il s’agit de prédire le mot suivant dans la séquence, on parle de prédiction du mot suivant ; s’il s’agit de prédire un mot manquant dans la séquence, on parle de modélisation du langage masqué.
Comme il s’agit d’une distribution de probabilités, il peut y avoir de nombreux mots probables avec des probabilités différentes. Même si l’on peut penser qu’il est idéal de toujours choisir le meilleur candidat avec la probabilité la plus élevée, cela peut conduire à des séquences répétitives. Dans la pratique, les chercheurs ajoutent donc une part d’aléatoire (température) lors du choix du mot parmi les meilleurs candidats.
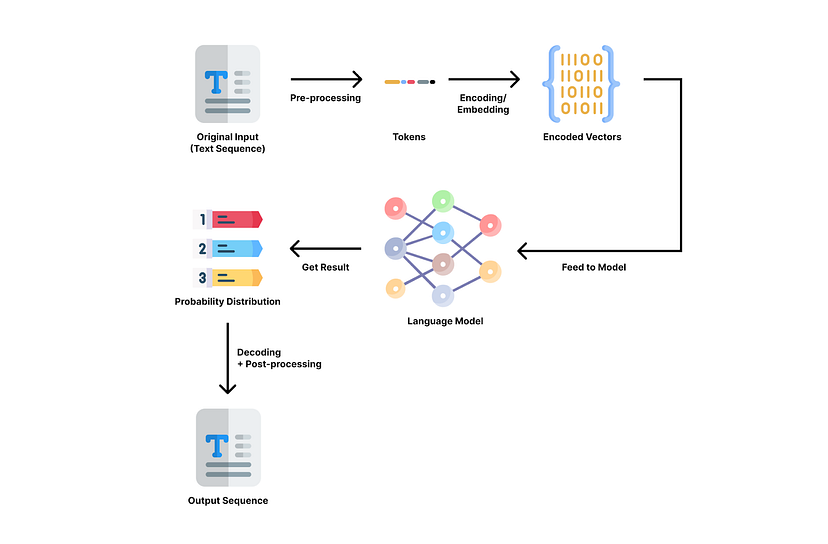
Processus NLP typique avec un modèle de langage. Image de l’auteur.
Dans un processus NLP typique, le texte d’entrée passe par les étapes suivantes [8] :
Prétraitement : nettoyage du texte à l’aide de techniques telles que la segmentation des phrases, la tokenisation (décomposition du texte en petits morceaux appelés tokens), le stemming (suppression des suffixes ou des préfixes), la suppression des mots vides, la correction de l’orthographe, etc. Par exemple, “Tom aime manger de la pizza” sera segmenté en [“Tom”, “aime”, “manger”, “pizza”, “.”] et transformé en [“Tom”, “aime”, “manger”, “pizza”, “.”].
Encodage ou incorporation : transformer le texte nettoyé en un vecteur de nombres, afin que le modèle puisse le traiter.
Alimentation du modèle : transmettre l’entrée codée au modèle pour traitement.
Obtention du résultat : obtenir du modèle le résultat d’une distribution de probabilité de mots potentiels représentés dans des vecteurs de nombres.
Décodage : retranscrire le vecteur en mots lisibles par l’homme.
Post-traitement : affiner le résultat avec une vérification orthographique, grammaticale, de la ponctuation, des majuscules, etc.
Les chercheurs en IA ont mis au point de nombreuses architectures de modèles différentes. Les transformateurs, un type de réseau neuronal, sont à la pointe de la technologie depuis quelques années et constituent la base du GPT. Dans la section suivante, nous allons examiner les composants et les mécanismes des transformateurs.
Architecture du transformateur
L’architecture du transformateur est la base des TPG. Il s’agit d’un type de réseau neuronal, qui est similaire aux neurones de notre cerveau humain. Le transformateur peut mieux comprendre les contextes dans les données séquentielles comme le texte, la parole ou la musique grâce à des mécanismes appelés attention et auto-attention.
L’attention permet au modèle de se concentrer sur les parties les plus pertinentes de l’entrée et de la sortie en apprenant la pertinence ou la similarité entre les éléments, qui sont généralement représentés par des vecteurs. S’il se concentre sur la même séquence, on parle d’auto-attention [2][9].
Le mécanisme d’attention mesure la pertinence/similarité entre chaque élément. Image de l’auteur.
Prenons l’exemple de la phrase suivante : “Tom aime manger des pommes. Il en mange tous les jours.” Dans cette phrase, “il” fait référence à “Tom” et “elles” fait référence à “pommes”. Et le mécanisme d’attention utilise un algorithme mathématique pour indiquer au modèle que ces mots sont liés en calculant un score de similarité entre les vecteurs de mots. Grâce à ce mécanisme, les transformateurs peuvent mieux “donner un sens” aux significations des séquences de texte d’une manière plus cohérente.
Les transformateurs ont les composants suivants [2] :
Embedding & Positional Encoding : transformer les mots en vecteurs de nombres.
Encodeur : il extrait les caractéristiques de la séquence d’entrée et analyse sa signification et son contexte. Il produit une matrice d’états cachés pour chaque jeton d’entrée à transmettre au décodeur.
Décodeur : génère la séquence de sortie sur la base de la sortie de l’encodeur et des jetons de sortie précédents.
Couche linéaire et couche Softmax : transforme le vecteur en une distribution de probabilité des mots de sortie.
L’encodeur et le décodeur sont les principaux composants de l’architecture du transformateur. L’encodeur est chargé d’analyser et de “comprendre” le texte d’entrée et le décodeur est chargé de générer la sortie.
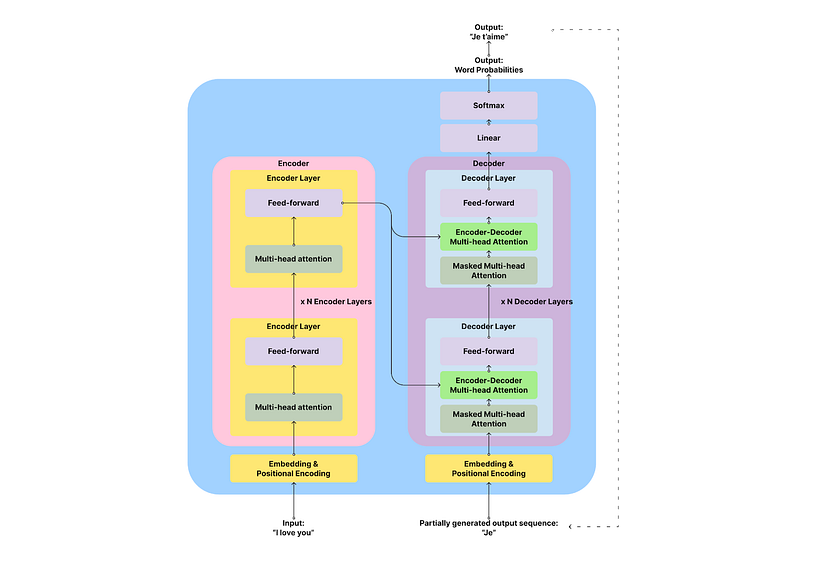
Illustration de l’auteur. Adapté de Attention is All You Need [2].
Si cela vous intéresse, vous pouvez poursuivre la lecture pour connaître les détails des encodeurs et des décodeurs. Sinon, n’hésitez pas à passer à la section suivante où nous aborderons les TPG, qui sont une variante des transformateurs.
L’encodeur est une pile de plusieurs couches identiques (6 dans l’article original sur les transformateurs). Chaque couche a deux sous-couches : une couche d’auto-attention multi-têtes et une couche de feed-forward, avec quelques connexions, appelées connexion résiduelle et normalisation de couche [2]. La sous-couche d’auto-attention multi-têtes applique le mécanisme d’attention pour trouver la connexion/similarité entre les jetons d’entrée afin de comprendre l’entrée. La sous-couche d’anticipation effectue un certain traitement avant de transmettre le résultat à la couche suivante afin d’éviter un ajustement excessif. Vous pouvez comparer les codeurs à la lecture d’un livre : vous faites attention à chaque nouveau mot que vous lisez et vous réfléchissez à la manière dont il est lié aux mots précédents.
Le décodeur est similaire à l’encodeur dans la mesure où il s’agit également d’une pile de couches identiques. Mais chaque couche du décodeur possède une couche d’attention supplémentaire entre les couches d’auto-attention et de rétroaction, afin de permettre au décodeur de se concentrer sur la séquence d’entrée. Par exemple, si vous traduisez “I love you” (entrée) en “Je t’aime” (sortie), vous devez savoir que “Je” et “I” sont alignés et que “love” et “aime” sont alignés.
Les couches d’attention à têtes multiples du décodeur sont également différentes. Elles sont masquées pour ne pas s’occuper de ce qui se trouve à droite du jeton actuel, qui n’a pas encore été généré [2]. On peut considérer les décodeurs comme une écriture libre : on écrit en fonction de ce que l’on a écrit et de ce que l’on a lu, sans se soucier de ce que l’on va écrire.
Des transformateurs aux GPT, GPT2 et GPT3
Le nom complet de GPT est Generative Pre-trained Transformer. D’après ce nom, vous pouvez voir qu’il s’agit d’un modèle génératif, bon pour générer des résultats ; il est pré-entraîné, ce qui signifie qu’il a appris d’un grand corpus de données textuelles ; c’est un type de transformateur.
En fait, le GPT utilise uniquement la partie décodeur de l’architecture du transformateur [3]. Dans la section précédente sur les transformateurs, nous avons appris que les décodeurs sont responsables de la prédiction du prochain token de la séquence. GPT répète ce processus encore et encore en utilisant les résultats générés précédemment comme entrée pour générer des textes plus longs, ce qui est appelé auto-régressif. Par exemple, si elle traduit “I love you” en français, elle génère d’abord “Je”, puis utilise le “Je” généré pour obtenir “Je t’aime”. (Voir la ligne pointillée dans l’illustration précédente).
Pour l’entraînement de la première version de GPT, les chercheurs ont utilisé un pré-entraînement non supervisé avec la base de données BookCorpus, composée de plus de 7000 livres uniques non publiés [3]. L’apprentissage non supervisé revient à demander à l’IA de lire elle-même ces livres et d’essayer d’apprendre les règles générales du langage et des mots. En plus de la pré-formation, ils ont également utilisé un réglage fin supervisé pour des tâches spécifiques comme le résumé ou les questions-réponses. Supervisé signifie qu’ils montrent à l’IA des exemples de demandes et de réponses correctes et lui demandent d’apprendre à partir de ces exemples.
Dans GPT-2, les chercheurs ont augmenté la taille du modèle (1,5 milliard de paramètres) et le corpus qu’ils alimentent avec WebText, qui est une collection de millions de pages Web, pendant le pré-entraînement non supervisé [4]. Avec un corpus aussi important pour apprendre, le modèle a prouvé qu’il pouvait être très performant sur un large éventail de tâches liées à la langue, même sans réglage fin supervisé.
Dans GPT-3, les chercheurs ont franchi une étape supplémentaire en étendant le modèle à 175 milliards de paramètres et en utilisant un énorme corpus comprenant des centaines de milliards de mots provenant du Web, de livres et de Wikipédia. Avec un tel modèle et un tel corpus en pré-entraînement, les chercheurs ont constaté que GPT-3 peut apprendre à mieux exécuter des tâches avec un (one-shot) ou quelques exemples (few-shot) dans le prompt sans réglage fin supervisé explicite.
(Si vous souhaitez en savoir plus sur la façon d’inciter les modèles à produire de meilleurs résultats, vous pouvez lire mon autre article : Comment utiliser IA générative dans la gestion de produit)
À ce stade, le modèle GPT-3 est déjà impressionnant. Mais il s’agit plutôt de modèles de langage à usage général. Les chercheurs ont voulu explorer comment il peut suivre des instructions humaines et avoir des conversations avec des humains. Ils ont donc créé InstructGPT et IA générative sur la base du modèle général GPT. Nous allons voir comment ils ont procédé dans la section suivante.
Apprendre aux GPT à interagir avec les humains : InstructGPT et IA générative
Après les itérations de GPT à GPT-3 avec des modèles et une taille de corpus croissants, les chercheurs ont réalisé que des modèles plus grands ne signifient pas qu’ils peuvent bien suivre l’intention humaine et peuvent produire des résultats nuisibles. Ils ont donc tenté d’affiner GPT-3 avec un apprentissage supervisé et un apprentissage par renforcement à partir du feedback humain (RLHF) [6][12]. Ces étapes de formation ont donné naissance à deux modèles affinés : InstructGPT et IA générative.
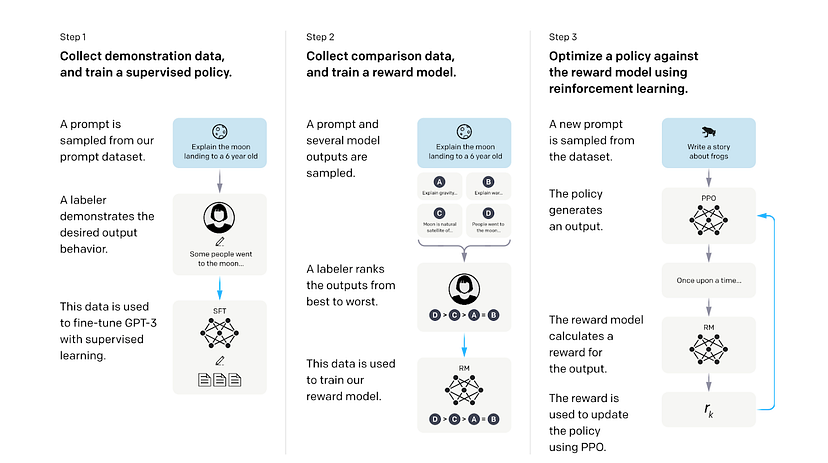
Illustration tirée de Training language models to follow instructions with human feedback [6].
La première étape est l’apprentissage supervisé à partir d’exemples humains. Les chercheurs ont d’abord fourni au GPT pré-entraîné un ensemble de données étiquetées de paires d’invites et de réponses écrites par des étiqueteurs humains. Cet ensemble de données est utilisé pour permettre au modèle d’apprendre le comportement souhaité à partir de ces exemples. Cette étape permet d’obtenir un modèle supervisé à réglage fin (SFT).
La deuxième étape consiste à former un modèle de récompense (RM) pour évaluer les réponses du modèle génératif. Les chercheurs ont utilisé le modèle SFT pour générer plusieurs réponses à partir de chaque invite et ont demandé à des étiqueteurs humains de classer les réponses de la meilleure à la pire selon la qualité, l’engagement, le caractère informatif, la sécurité, la cohérence et la pertinence. Les invites, les réponses et les classements sont transmis à un modèle de récompense pour apprendre les préférences humaines des réponses par apprentissage supervisé. Le modèle de récompense peut prédire une valeur scalaire de récompense en fonction de la mesure dans laquelle la réponse correspond aux préférences humaines.
Dans la troisième étape, les chercheurs utilisent le modèle de récompense pour optimiser la politique du modèle SFT par apprentissage par renforcement. Le modèle SFT génère une réponse à partir d’une nouvelle invite ; le modèle de récompense évalue la réponse et lui attribue une valeur de récompense qui se rapproche des préférences humaines ; la récompense est ensuite utilisée pour optimiser le modèle génératif en mettant à jour ses paramètres. Par exemple, si le modèle génératif génère une réponse que le modèle de récompense pense que les humains pourraient aimer, il recevra une récompense positive pour continuer à générer des réponses similaires à l’avenir, et vice versa.
Grâce à ce processus d’apprentissage supervisé et d’apprentissage par renforcement à partir de la rétroaction humaine, le modèle InstructGPT (avec seulement 1,3 milliard de paramètres) est capable d’obtenir de meilleurs résultats dans les tâches qui suivent des instructions humaines que le modèle GPT-3, beaucoup plus gros (avec 175 milliards de paramètres).
(Remarque : cela ne signifie pas pour autant qu’InstructGPT est meilleur que GPT-3 dans tous les aspects ou domaines. Par exemple, GPT-3 peut encore avoir un avantage dans la génération de textes plus longs ou plus créatifs, tels que des histoires ou des articles).
IA générative est un modèle frère de InstructGPT. Le processus de formation est similaire pour IA générative et InstructGPT, y compris les mêmes méthodes d’apprentissage supervisé et de RLHF que nous avons abordées précédemment. La principale différence réside dans le fait que IA générative est entraîné à l’aide d’exemples de tâches conversationnelles, telles que la réponse à des questions, le bavardage, le trivia, etc [7]. Grâce à cet entraînement, IA générative peut avoir des conversations naturelles avec des humains dans des dialogues. Au cours des conversations, IA générative peut répondre à des questions de suivi et admettre ses erreurs, ce qui rend l’interaction avec lui plus intéressante.
À retenir
Grâce aux explications précédentes, j’espère que vous avez une meilleure compréhension du fonctionnement du modèle de IA générative et de son évolution vers ce qu’il est aujourd’hui.
En guise de récapitulation rapide, voici les points les plus importants à retenir et les limites des modèles de TPG :
IA générative est basé sur un modèle de transformateur auto-régressif de décodeur uniquement pour prendre une séquence de texte et sortir une distribution de probabilité des tokens dans la séquence, en générant un token à la fois de manière itérative.
Comme il n’a pas la capacité de rechercher des références en temps réel, il fait des prédictions probabilistes dans le processus de génération sur la base du corpus sur lequel il a été entraîné, ce qui peut conduire à de fausses affirmations sur les faits.
Il est pré-entraîné sur un énorme corpus de données Web et de livres et affiné avec des exemples de conversation humaine par apprentissage supervisé et apprentissage par renforcement à partir du feedback humain (RLHF).
Ses capacités sont principalement basées sur la taille de son modèle et sur la qualité et la taille du corpus et des exemples à partir desquels il a appris. Avec un apprentissage supervisé supplémentaire ou un renforcement de l’apprentissage à partir du feedback humain, il peut être plus performant dans des contextes ou des tâches spécifiques.
Étant donné que le corpus provient de contenus Web et de livres, il peut présenter des biais dont le modèle peut tirer parti, notamment des biais sociaux, culturels, politiques ou liés au sexe, ce qui entraîne des réponses biaisées à certaines demandes.
Restez curieux et ouvert aux nouvelles technologies comme IA générative. Je pense qu’un état d’esprit ouvert et la curiosité peuvent nous aider, nous les gestionnaires de produits non techniques, les concepteurs et les entrepreneurs, à naviguer sur cette nouvelle vague de révolution technologique.